Personal Projects
This section showcases personal and academic projects. Click any card to explore the full project.
SummonRun — iOS Running App
- Designed, built, and shipped a gamified running app on the App Store that pairs with Apple Health and turns each qualifying run into evolution progress for a monthly mythical creature.
- Built the full stack solo: React 19 + TypeScript + Vite frontend wrapped in Capacitor for iOS, Supabase (Postgres + Auth + Deno Edge Functions) backend, and custom Swift plugins for HealthKit, Sign in with Apple, StoreKit 2 IAP, APNs push, and local notifications.
- Shipped an Apple Watch companion app with complications (Circular, Rectangular, Inline, Corner), an iOS Home Screen widget, in-app camera with creature overlay, and a friend leaderboard ranked by creature progress rather than pace.
- Implemented a gacha collection system (25+ secondary creatures across five rarities including a limited Founder Dragon), six animated elemental island habitats with three upgrade tiers each, 31 achievements, and a Creature Codex.
- Live on the App Store: apps.apple.com/us/app/summonrun. Landing page: summonrun.com.

CollabScanner — AI Influencer Outreach SaaS
- Designed, built, and shipped a full-stack B2B SaaS that helps marketing teams automatically scan their email inboxes for creator/influencer collaboration requests, extract key details with AI, and manage them through a campaign pipeline.
- Built the entire stack solo: React + Vite frontend (Vercel), Node.js + Express backend (Railway), PostgreSQL on Supabase, Supabase Auth, and Stripe subscriptions with metered plan tiers, upgrades/downgrades via Subscription Schedules, and proration.
- Integrated the Unipile API for secure read-only Gmail & Outlook OAuth, scanning 30 days of email in paginated batches, then used OpenAI (GPT-4o-mini) to distinguish genuine creator pitches from newsletters, sales emails, and agency spam — auto-extracting names, social handles, follower counts, niches, rates, and collaboration type.
- Engineered team collaboration features: organizations with role-based access, real-time activity feeds over WebSockets, shared campaigns, deliverables, a deadline calendar, follow-up detection, and a per-user drag-and-drop workflow pipeline.
- Hardened the product for production: SHA-256 bearer-token sessions, LLM prompt-injection sanitization with output-schema validation, parameterized queries, rate limiting, callback-secret verification, and an 80-test Jest suite.
- Live at collabscanner.com (app at app.collabscanner.com).

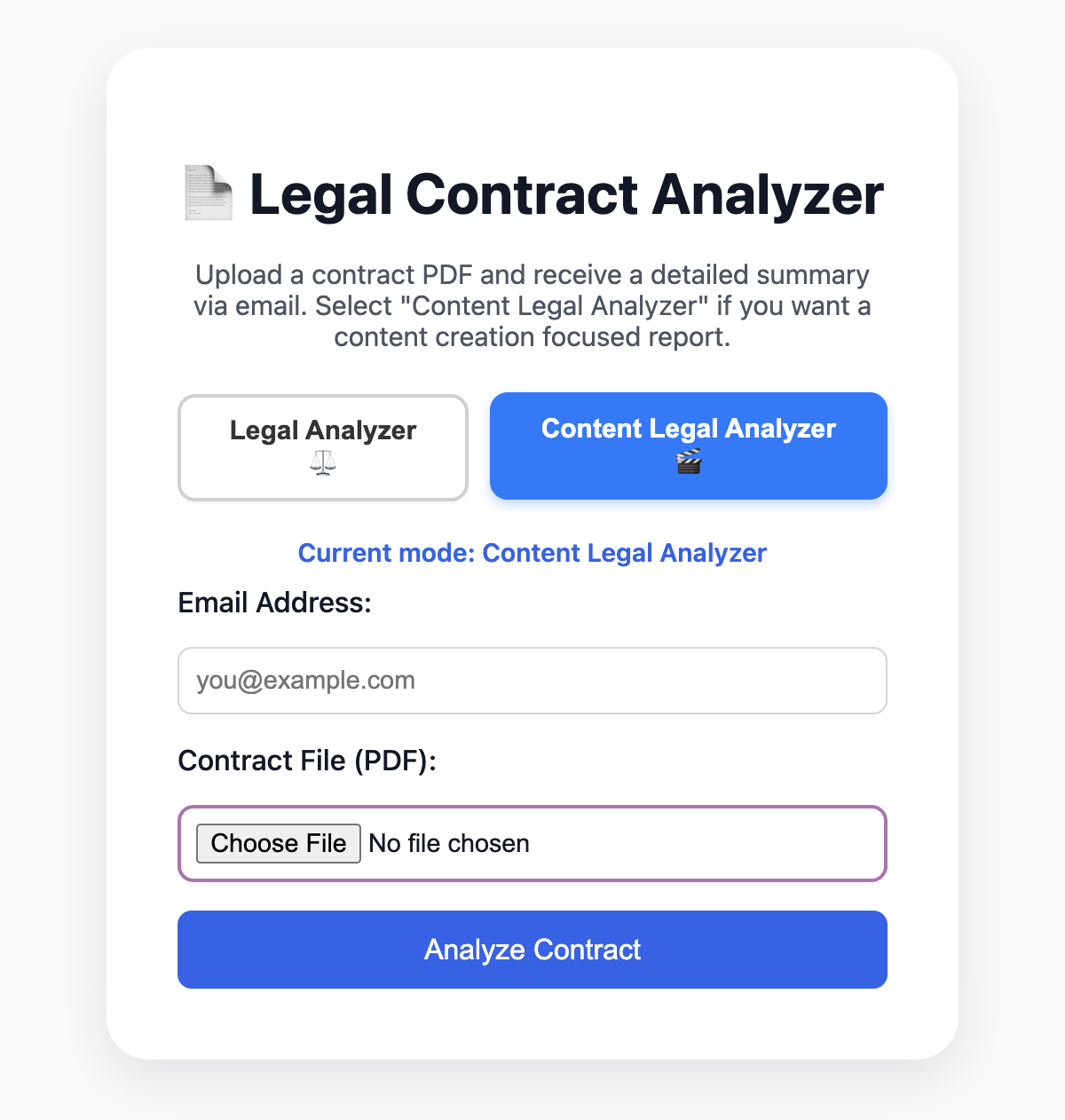
AI Legal Contract Analyzer
- Built an AI-powered contract analysis system using LangGraph and GPT-5-mini that automatically parses PDFs, identifies risks, and generates comprehensive summaries
- User-facing web interface (HTML + CSS + Flask backend) allows users to upload a contract PDF and enter an email address for the report.
- Developed intelligent research system where LLM identifies unclear terms in contracts, triggers web searches via DuckDuckGo API, and generates creator-friendly explanations
- Integrated Google Calendar API to auto-create deliverable reminders and SMTP email delivery for professional markdown summaries
- Deployed as a secure web application on Railway here, providing a password-protected interface for a single client to upload contracts.
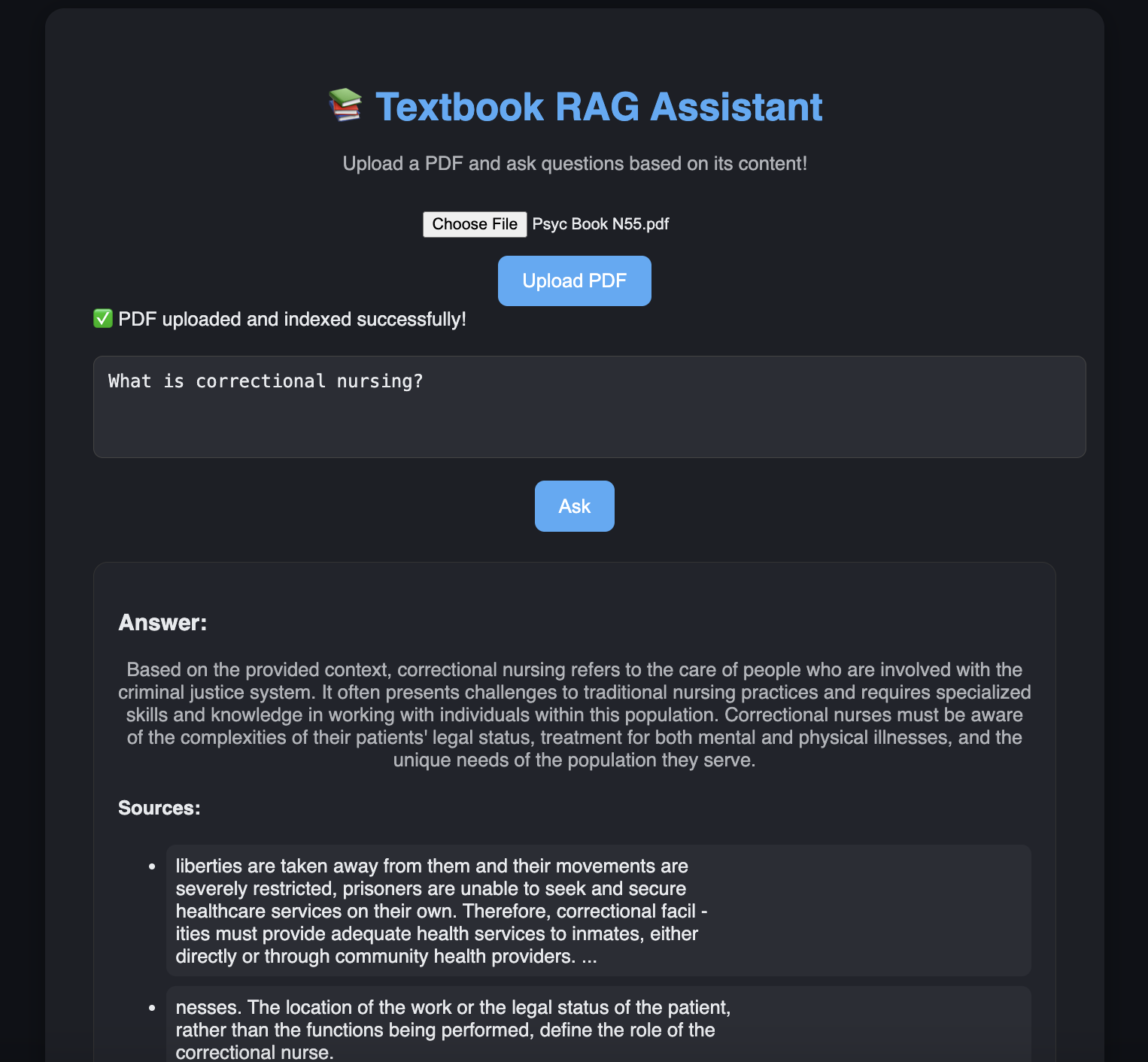
RAG Textbook Assistant
- Developed a Retrieval-Augmented Generation (RAG) system that enables users to upload textbooks or PDFs, automatically process them into searchable chunks, and generate semantic embeddings using FAISS and HuggingFace models.
- Leveraged LangChain to orchestrate document loading, text splitting, embedding creation, and retrieval-based question answering through a modular pipeline.
- Integrated a local LLM (via Ollama: llama3.2) within a Flask web interface, allowing users to ask natural language questions and receive context-grounded answers sourced directly from the uploaded documents.
- Cannot link to app as I do not have a server to host this outside of my local machine.
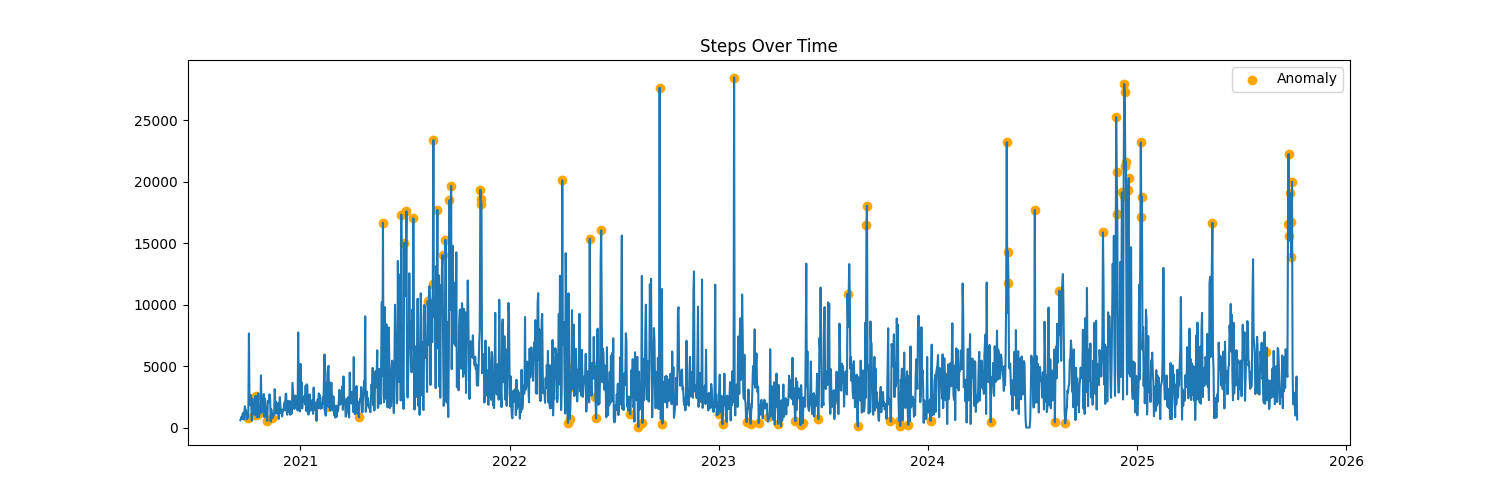
Anomaly Detection: Abnormal Exercise
- Analyzed iPhone health data (2018–2025) to detect unusual exercise days.
- Trained Isolation Forest model (5% contamination) for anomaly detection.
- Identified anomalies matching high-activity events (e.g., Korea trip).
- Built modular Python pipeline and deployed visual results via HTML/CSS.
Challenging the Limits of NLP: Addressing Adversarial Vulnerabilities in Language Models
- Goal: Investigated adversarial vulnerabilities in NLP models by testing and improving the ELECTRA-small model on natural language inference (NLI) tasks. Project for NLP class at UT Austin.
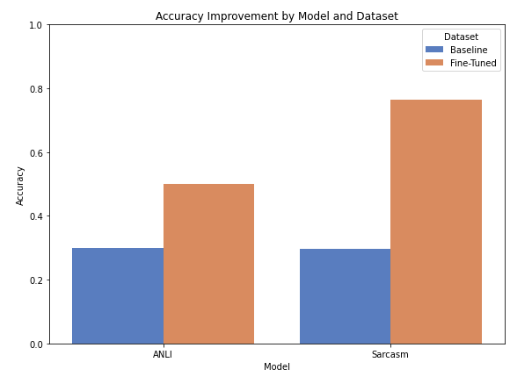
- Findings: The baseline model achieved 89.3% accuracy on standard NLI data but dropped to 29.9% on adversarial examples, revealing weaknesses in true semantic understanding.
- Approach: Improved robustness through fine-tuning on adversarial datasets (ANLI and sarcasm-specific data), boosting performance on adversarial tasks by up to +47% accuracy.
- Impact: Demonstrated that targeted fine-tuning mitigates bias from token overlap and strengthens comprehension of nuanced language, contributing to more human-like NLP reasoning.
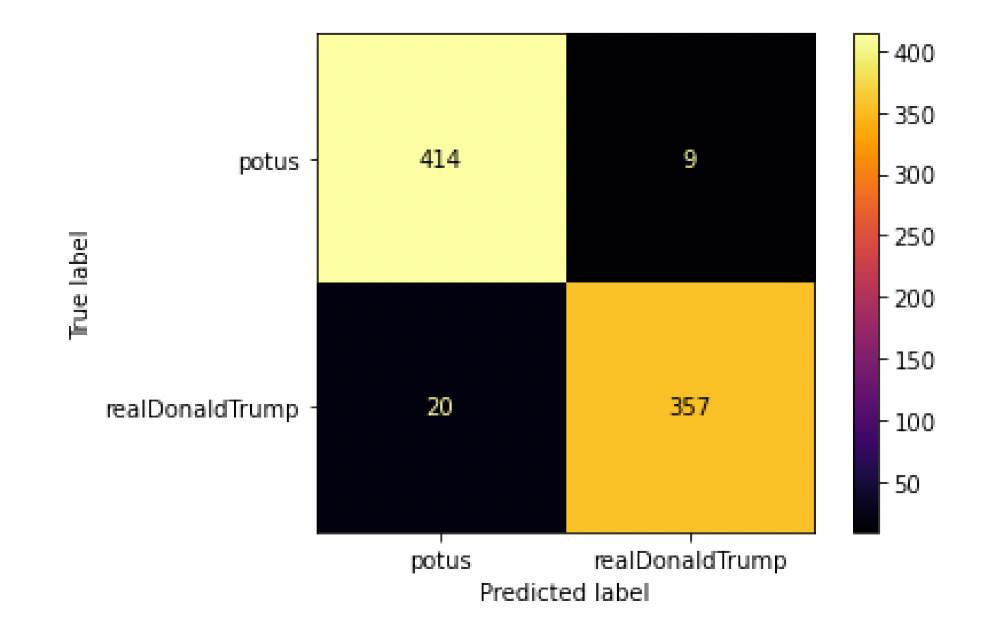
Trump or Biden? (NLP Tweet Classifier)
The goal of this project was to build a classifier that predicts whether a specific tweet was written by Donald Trump or Joe Biden. The three classifiers that were used were a Naive Bayes Model, a Support Vector Machine, and a Logistic Regression.
- Naive Bayes: 95.125%
- Support Vector Machine: 96.375%
- Logistic Regression: 94.875%
Forecasting Short-Term Future COVID-19 Cases
Goal:
- Create two time-series forecasting models that predicts the number of new daily COVID cases in each county.
- Models were trained on the estimated percentage of outpatient doctor visits with confirmed COVID, outpatient doctor visits primarily about COVID-related symptoms, and new hospital admissions with COVID-associated diagnoses: all for 15 counties in California from May 1st, 2020 to November 1st, 2021.
- Created both an interpretable model in a decision tree regression model as well as a more complex model in a support vector regression model.
Conclusion:
- Decision Tree Regressor testing RMSE was 908.86 and its R-squared value was approximately 0.57.
- Support Vector Regressor produced a testing RMSE of 1403.20 and an R-squared value of approximately -0.025.
- Neither model accurately predicted the number of new daily COVID cases per county using historical data due to wide range of values of the original dataset in addition to the features simply not being good predictors of new COVID cases.
- Decision tree performed much better than the SVR model as it was able to capture the overall trend in the rise and fall of new daily COVID cases.
- Link to poster here.

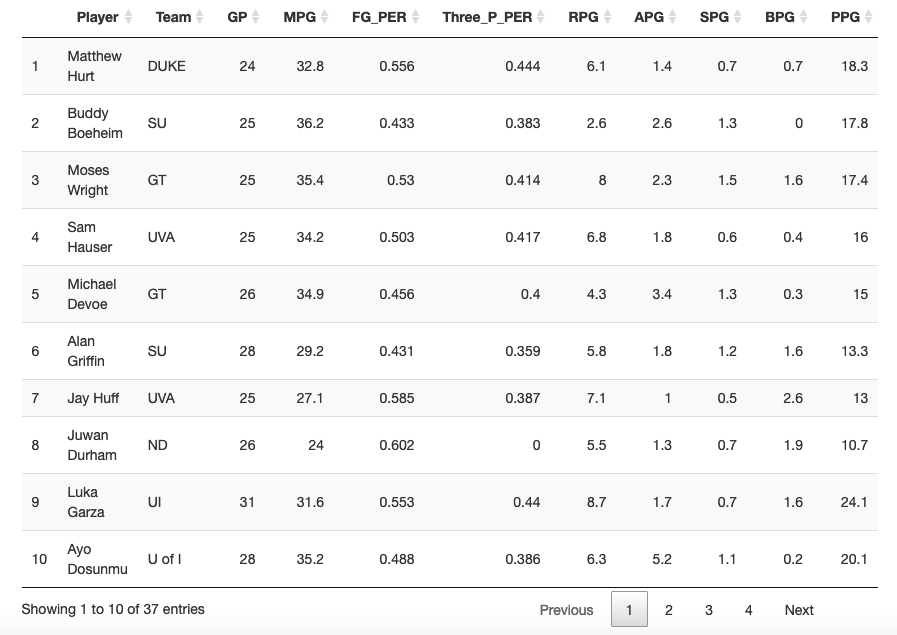
Predicting The 2021 NBA Draft
- The goal of this project was to use preexisting data from the 2019 NBA draft in addition to NCAA college basketball statistics as a way to create the best classification model to predict whether or not a player would be chosen in the 2021 NBA draft. I found that the best model out of the ones that I attempted was a logistic regression that used an optimal threshold. This model had a 93% overall accuracy rate and an 80% true positive rate on the 40% test data split, which was the highest out of all the models considering the overall accuracy was not lowered too drastically. On July 29th, I will come back to this project as a way to see how many of the 37 individuals that my model predicted to be drafted are actually drafted to the NBA.
- Edit (Post July 29, 2021): Out of the 37 players that my model predicted to be drafted, only 8 of them were actually drafted leaving us with a 21.6% accuracy rate. With that being said, there 10 players who I predicted to be drafted who went undrafted but eventually signed with NBA G-League teams or are currently on an NBA roster. Many of the players that I predicted to be drafted actually ended up not even entering the draft and stayed at their respective schools. In the datatable, I have highlighted the players that were officially drafted by NBA teams in the 2021 draft.
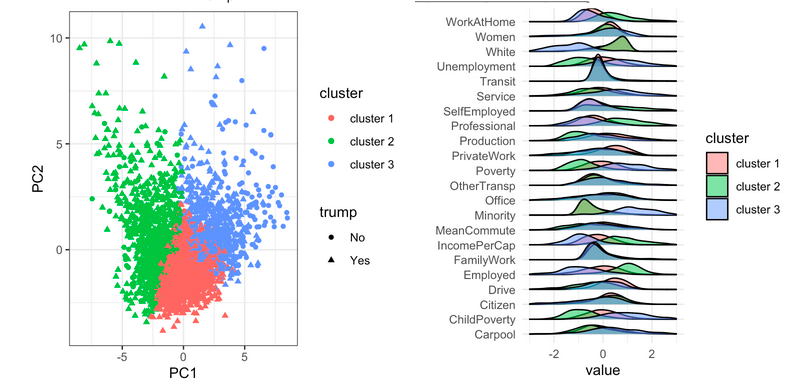
Predicting the 2016 Presidential Election Using Demographic Data
Goal #1: Predicting whether or not Donald Trump would win a specific county
- Linear Regression: 0.09 RMSE / Predicted Trump would win 548/613 counties in the test dataset which is 21 more than he actually won.
- Logistic Regression: 91.4% Accuracy
- Random Forest: 92.2% Accuracy
- Adaptive Boosting: 92% Accuracy.
Goal #2: Use K-Means clustering to cluster our data and see if there were any distinct groups driven by specific demographic variables
- Top two clusters that had the highest percentage of counties vote for Trump, were also predominantly white and wealthy.
- The cluster with the lowest percentage of counties that voted for Trump was driven by a higher population of minorities and individuals with lower income per capita.
Evaluating Disney's Pricing Model
Simple data analysis project done in order to calculate the price elasticity of demand for Disney World single day passes over the past decade using attendance records and average prices. Doing this allowed me to make conclusions about Disney's pricing strategy relating to their theme parks.
December 2020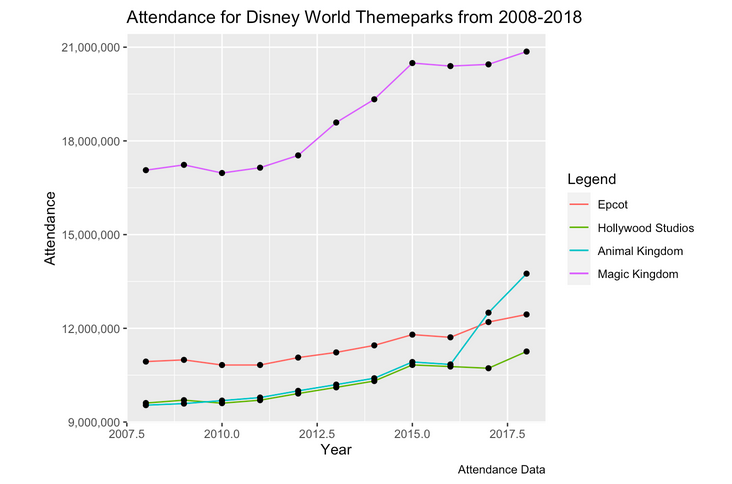
Spotify Recommender: Ordering Playlists
UCSB Data Science Club Project. Through this project, my group and I wanted to see if we could order a Spotify playlist based on similarity to another playlist. In order to do this, we got numerical data from our Spotify playlists and calculated the error between the numerical values of songs from the second playlist and the average, median, and mode values from the first. This allowed us to make predictions as to which songs were most similar to the playlist.
November 2020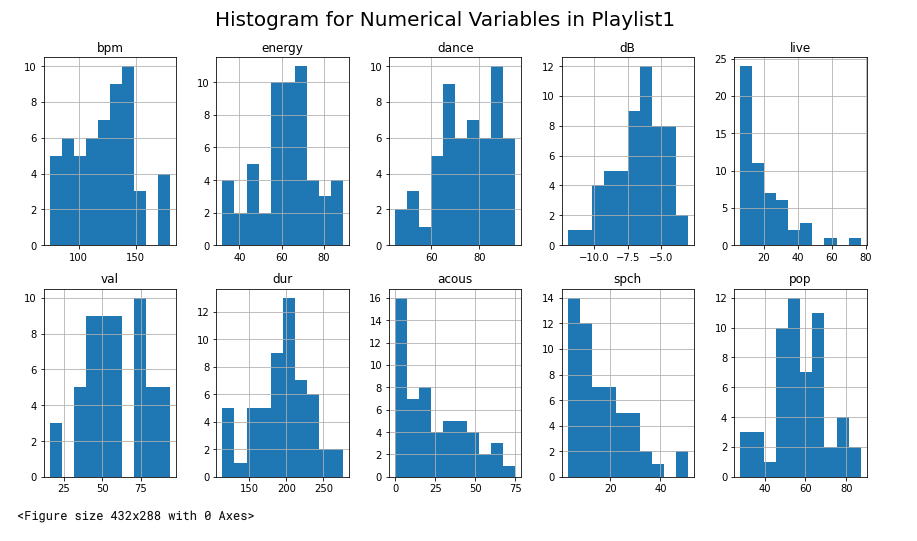
Mitigation Strategy Proposal: Solar Panels
Honors Contract Project. In this project, using a combination of data science methods and thorough research, I proposed a mitigation strategy that requires certain homeowners, based on the purchase price of their house, to install solar panels as a way of reducing carbon emissions.
October 2020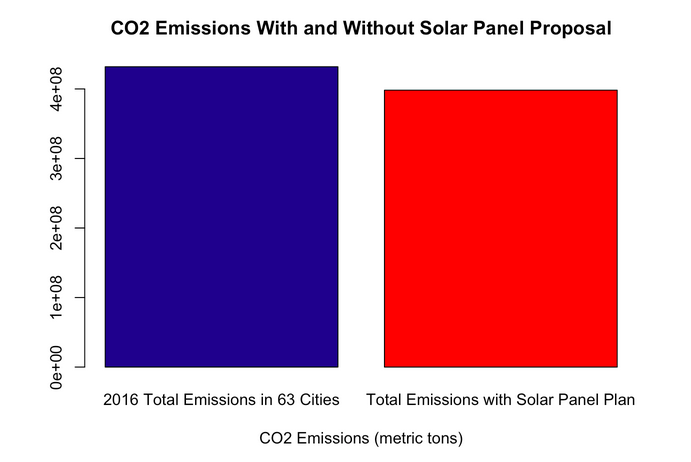
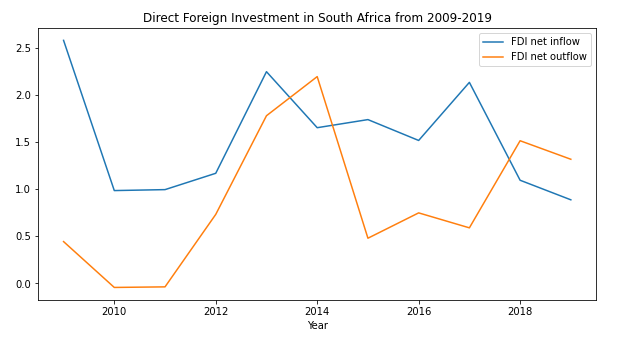
UC x Imagine Datathon Project
Right before Fall quarter 2020, I participated in a Datathon hosted by the UC system and ImagineScholar. The goal of this project was to analyze and visualize data about energy and load shedding in South Africa. My partner and I decided to see if there is a correlation between instances of load shedding and international/foreign investment to see if load shedding was impacting the economy.
August 2020